시작 하기 전…
혹시 “디자인 초보의 험난한 디자인 개선기”를 읽지 않았다면, 지금 개발하는 HackRSS가 무엇인지에 대한 간단한 설명과 왜 이렇게 하고 있는지에 대해 아주 조금 더 이해할 수 있기 때문에 꼭 읽고 이 게시글도 읽었으면 좋겠다!
개요
자, 이제 “디자인 초보의 험난한 디자인 개선기”에서 그린 시안을 직접 React로 구현해보자. 기존에 작업했었던 코드는 전부 날렸다! 프론트부터 백엔드까지! 프론트의 경우 JS에서 React로 변경되어 처음부터 깔끔하게 시작하기로 하였고, 백엔드는 겸사겸사 새로운 기능들이 추가되며 리팩토링 할 겸 초기화했다.
개발 상황
다행히도 내가 개선 작업에 참여했을 때 보다 인원이 조-금 늘었다! 하지만 추가된 인원들이 개발자는 아니라서 두명이서 작업했다. 둘이 모여야 React 코드가 완성되기 때문에 우리는 이 상황을 “풀스택 개발자”에 빗대어 “하프스택 개발자”라고 표현했다.
우리끼린 정말 웃었다. 재미 없다면 심심한 사과를…
개발
특별히 뭐 React에 대해서 적을 건 없다. 나보다 더 똑똑한 사람들이 이미 많이 정리해 놨기 때문에… (Velopert님 책 정말 좋아요! 많이 배웠습니다!) 나는 그냥 개발하면서 느꼈던 것들을 소소하게 적어보려고 한다.
참고로 내가 맡은 부분을 어떻게 설명해야할지 모르겠어서 그냥 대충 절반은 내가 했다.
시작하며 느낀것
기간
2020년 6월 18일에 개발을 시작해서 2020년 12월 22일에 완성하였다. 원래 목표는 프론트만 개발하는 걸로 7월내 개발 완료였는데, 백엔드 개발이 추가되며 일정이 밀렸다. 게다가 개발만 하면 나오는 문제점들이 발목을 잡았다. 자세한건 아래 항목들에서 설명하겠다. 그렇게 미루고, 새로 개발할 내용이 추가되고 하다보니 결국 12월까지 밀렸다. 일정은 넉넉하면서도… 올바른 설계와 함께 설정되어야 한다는 것을 느꼈다.
설계의 중요성
매번 느끼는 것이지만… 개발을 할 때는 설계를 열심히 해야한다. 특히, 초급 개발자라면 더더욱…! 화면설계서와 API 명세서, DB 정도는 필수적으로 완성해놓고 개발을 시작해야 편하다고 생각한다.
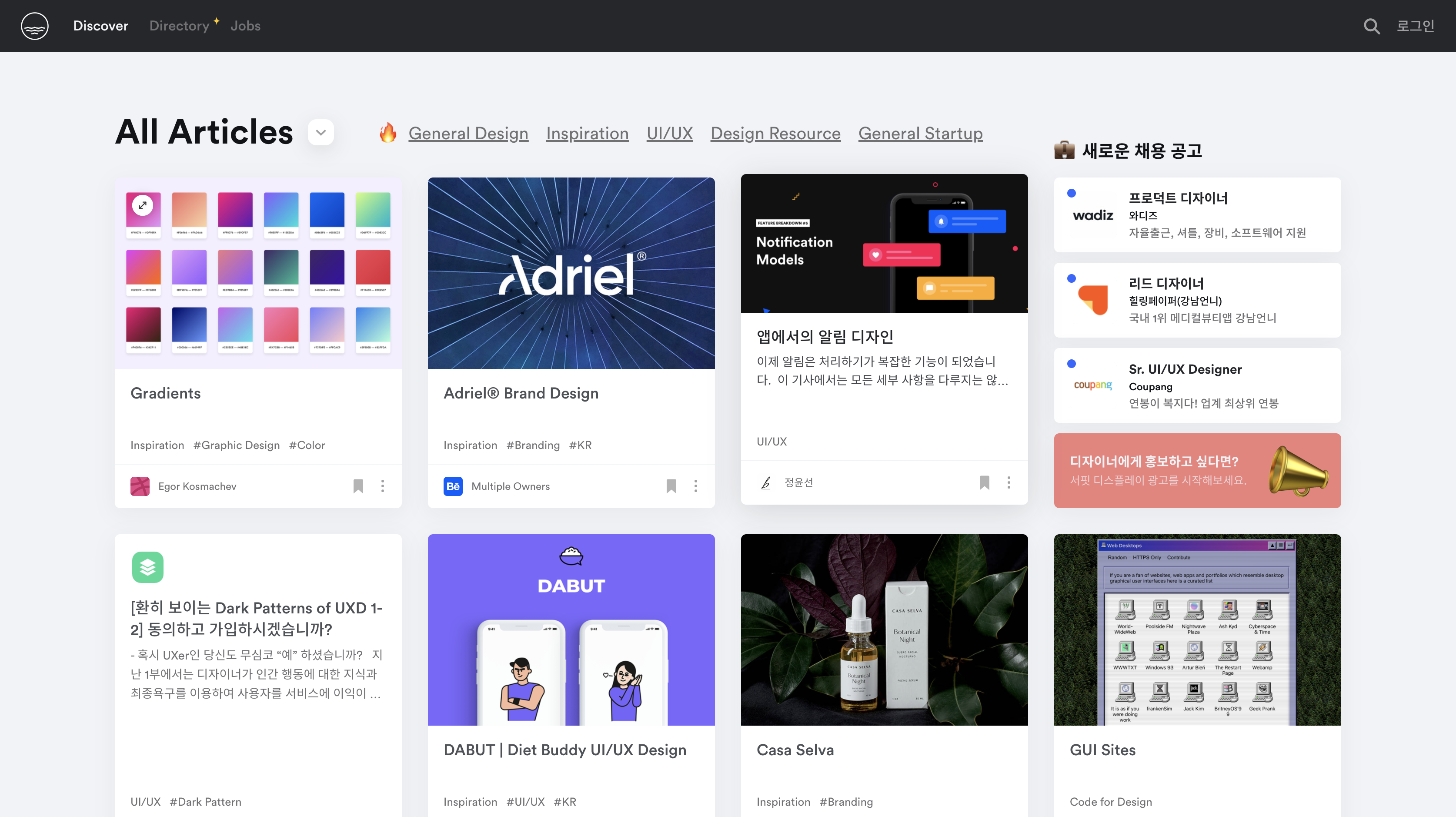
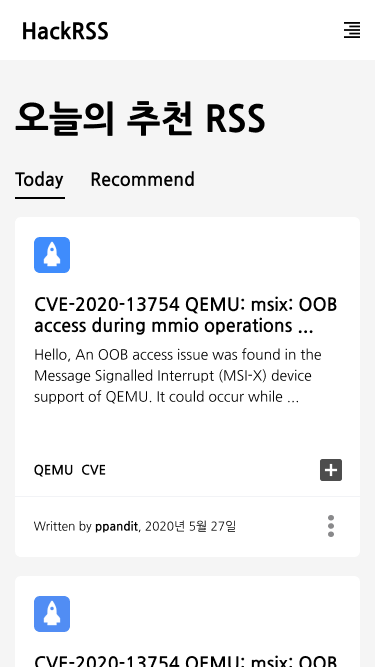
이번 HackRSS 개발에서는 Figma를 사용하여 메인페이지와 일부 동작들에 대한 설계를 완료하고 개발을 진행하였다. 약 50%정도 완료한 상태에서 개발을 시작하였는데, 후반부 작업으로 갈 수록 문제가 생겼다.
그려둔 디자인을 실제로 구현해서 다양한 해상도에서 보았을때 어색해진 점이 있었다던가, 중간에 기능이 변경되서 임기응변으로 고쳐서 구현해야 했다던가… 구현 자체가 난이도가 있어서 대체한 경우도 있었다.
물론 완벽한 설계라는건 존재할 수 없겠지만, 최소한 그 시점에서 제시된 기능들에 대한 설계 작업을 완료하고 이에 대한 검토 작업까지 마무리하고 개발에 들어가는 것이 좋겠다고 느꼈다.
협업툴의 중요성
이슈 트래커의 중요성
개발자라면 Git의 Issue를 잘 활용하면 되지만, 팀 프로젝트라 개발자 이외의 사람들도 포함되어 있어 외부 이슈 트래커를 사용했다. 이번에 사용한건 Asana를 사용했는데, 꽤 마음에 들었다. 부가적인 기능들은 유료지만, 무료 기능을 사용하면서도 부족한 점은 없었다.
개인적으로는 Git과 연동이 되는 이슈 트래커를 사용했으면 좋겠다는 생각은 있지만, 팀 활동이라는게 여러 사람이 함께 사용하는 것이니 그정도는 괜찮았다.
오히려 늦게 사용해서 조금 아쉬웠고, 귀찮다고 마감일 지정을 안해두고 사용해서 까먹는 경우가 많았다. 아무튼… 이슈 래커 중요하다! 꼭 계획대로 잘 사용하자!
SourceTree
VS Code에도 Git 관련 기능을 붙일 수 있지만, 탐탁치가 않았다. 이번 작업에서는 SourceTree를 적극적으로 활용했다. 매우 만족하고 있지만, 맥 버전과는 다르게 윈도우 버전의 안정성이 너무 좋지 못했다.
대부분의 작업을 맥에서 하긴 했지만, 윈도우에서 꼭 확인은 해봐야 했기 때문에 좀 불편했다. 윈도우에서는 Github Desktop을 사용했는데 이것도 뭐 괜찮았다.
Git은 뭐… 사실 CLI 사용해도 되는거라 취향의 차이지만, 아무래도 커밋 그래프 같은 것을 바로 확인할 수 있다는 점에서 사용하는 것이 효율이 더 좋은 것 같다.
내가 만든 디자인한 것을 구현하며 느낀것
Material-UI
나 같은 경우에는 대부분의 CSS를 styled-component를 이용하는 것을 선호한다. 배경색과 폰트 정도만 글로벌 CSS를 수정하고 나머지는 하나하나 지정하며 개발했다. 그러다보니 Dropdown을 추가할 때 문제가 있었다. 내가 원하는 기능들을 가지고 있는 적당한 패키지들을 찾아 나섰는데 찾을 수가 없었다.
게다가 Bootstrap이나 Sementic-UI 같은 프레임워크를 쓰면 CSS가 다 깨져서 사용할 수 없었다. (물론 내가 잘 못 쓰는 것 일 수도?) 이런 문제들을 Material-UI가 모두 해결해주었다! 기능도 충분하고, CSS도 안깨지고! 정말 최고다!
이 밖에도 대부분의 기능에서 Material-UI를 이용하여 초기 구현을 마쳤지만… 정말 내가 원하는 대로 구현하려면 역시 직접 구현해야한다는 생각을 하게 되었다. 시간적 여유가 있다면, 아마 하나하나 대체해 나갈 것 같다.
그림과 구현물의 차이
내가 그린 디자인 시안대로 보고 만들지만, 그대로 만들기는 정말 어려웠다.
왜 이런 문제가 발생했을까에 대해 고민을 해봤는데, 결국은 비율의 문제라는 결론을 내렸다. 설계 단계에서 사용자들이 자주 사용할 것으로 예상되는 해상도의 화면 설계를 준비하는 것이 이런 문제점을 해소할 수 있을 것 같다.
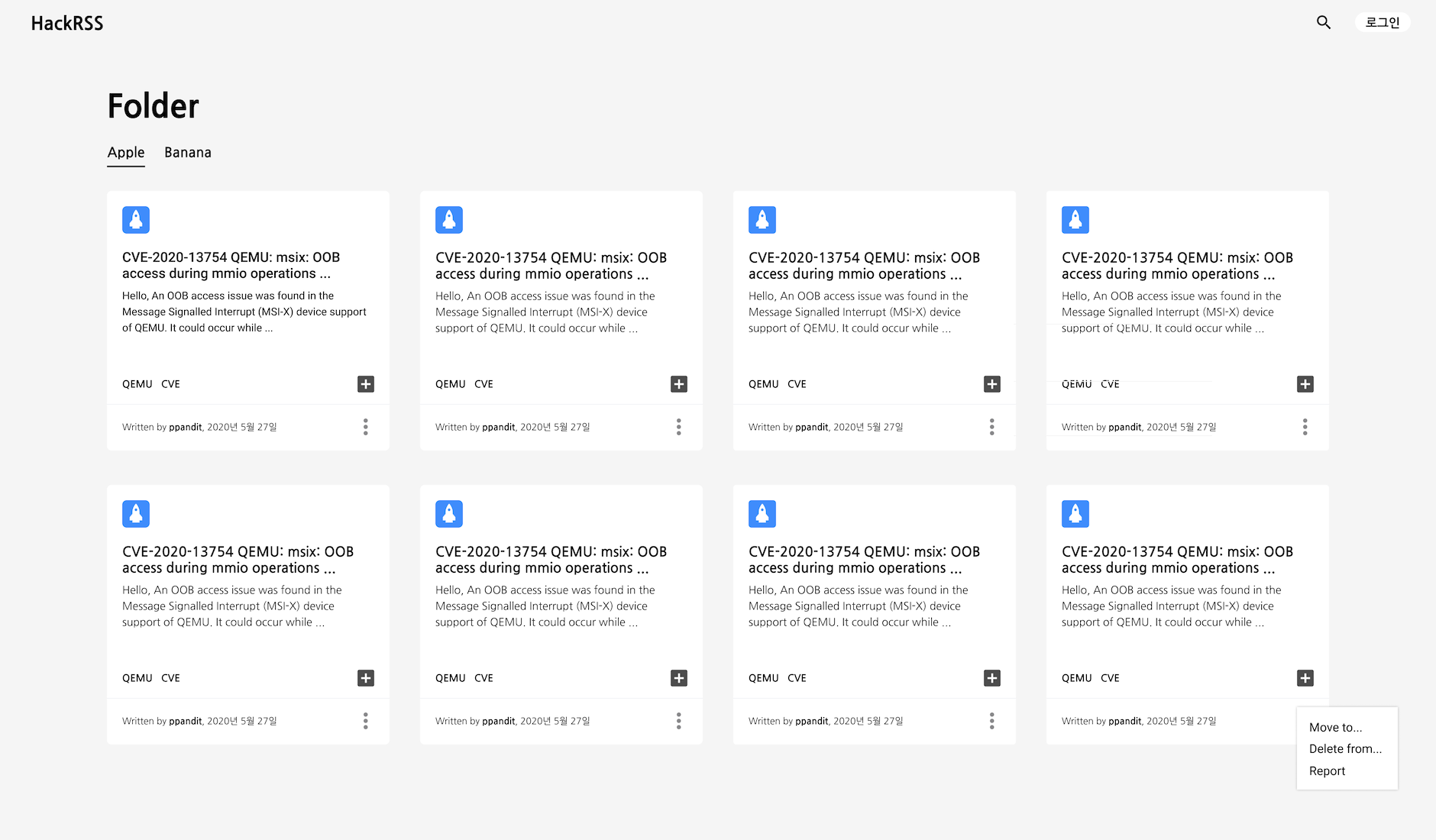
특히, HackRSS에서는 RSS를 보여주는 박스의 크기가 유동적인데 이에 대한 고민을 너무 하지 않은 것 같다. 당장은 아쉽지만… 추후에 꼭 수정해야겠다고 생각하고 있다. 모바일과 PC 모두에서 편한 UX를 고민해야겠다.
미디어쿼리는 한 사이즈 크게…
반응형 웹을 준비하면서 미디어쿼리를 세팅할 때 잘못 생각한 부분이 있었다.
max-width:1920px와 max-width:1600px를 작업한다면, 1920px에서 사용할 옵션을 1600px에 넣어야한다! 물론 모든 경우는 아니고, 나와 같이 박스 사이즈가 작아진다면… 1600에서 300px로 예상한 박스 사이즈가 너무 커지거나 작아지는 경우가 발생! 다음부터는 최소-최대 사이즈를 적절하게 고려해서 해야겠다.
사실 아닐 수도 있는데… 검색을 해봐도 명퀘한 해답이 없었고, 내가 남들과 생각하는게 조금 다른가보다… 아무튼 그랬다.
Redux는 필수인가? 그렇다.
사실 처음에는 왜 꼭 써야한다고 하는지가 와닫지 않았다. 직접 구현해보고서야 느끼게 되었다. 초기 세팅이 조금 힘들긴 해도, 관리 측면에서 보면 너무 편했다.
다만… 설계 부족이 여기서도 문제를 일으켰던 것 같다. Redux 쪽은 중반부 개발까지 다른 팀원(그래봤자 2인 개발)이 맡았다가, 후반부 작업에서 내가 이어받았는데 설계 자체가 없던 기능을 구현하려고 하니 내공 부족으로 조금 힘들었다. 지금 되돌아보면 조금 더 최적화(?)를 할 수 있었을 것 같은데, 너무 낭비해서 구현한 느낌이다.
Pages-Containers-Components와 중구난방으로 넘어다니는 props
이 글을 올리고 나서 직후에 할 작업이 바로… 내부 구조 개선이다…
이것도 설계 부족의 여파인 것 같은데… 중간에 내가 내부 구조를 한번 바꾸자고 해서 한번 바꾸고, 통합할 수 있어보이는 components들이 있고, 분리할 수 있는 components들이 보여 이 작업을 수행했었는데… 이게 더 복잡하게 만들어 버린 것 같다.
사실 구조의 정답은 모르겠다. 유명한 사람들이 짜둔 코드 구조를 보고 이렇게 하면 되겠구나를 배운거라… 그래도 일관성 있는 구조를 유지해야, 추후 다른 개발자가 투입되도 쉽게 알아볼 수 있을 것 같아… 여기에도 남겨둔다.
꼭… 처음에 설계를 잘 하고 시작해서 이런 구조도 합의를 잘 하고 시작하자!
남은 후속 개발들…
아직 개발할 기능들이 많-이 남아있다. 유지보수 하면서 하나하나 기능들을 추가시켜 나가보며 더 공부해야겠다.
광고
구글 애드센스 정말 귀찮다… 아직도 못달았다… 들어갈 공간을 마련해야 승인을 받는데… 이게 정말 마땅치가 않네~
끝
개발을 어떻게 했다…를 이렇게 써보는 것이 처음이라 어떻게 써야할지 모르겠다. 오픈소스도 아니니 공개도 못하고… 참고 자료를 올려가며 설명을 하고싶어도… 대부분 코드니 또 애매하다 _ 아무튼 HackRSS 개발기는 여기서 마무리한다. 끝!
완성본
https://hackrss.kr/ 에서 확인 가능!